CPSC 225, Spring 2016
Lab 12: Web College
In this week's lab, you will work on a program that combines networking with threads. The program will "crawl" the web, looking for images and for links to more web pages. Images that are found will be added to an "image collage."
You should create a new Lab12 project and copy the files from inside the folder /classes/cs225/Lab12-files. You will be working on the program WebCollage.java. The other two files, LinkParser.java and WebCollagePanel.java, are used by that program, but you won't have to modify them. You can find an executable jar file with the completed program in /classes/cs225/WebCollageComplete.jar.
This lab is due after Thanksgiving, by 9:00 AM on the morning of Saturday, December 3. This is an individual assignment. This lab should not take a large amount of time. You really should be working on your final project.
About the Web Crawler
If you run the WebCrawler program now, it will ask you for a web page URL. It will download the page and find any links on the page that lead to images, but it will just discard any links that do not lead to image. It will download the images from the web and add them to a display panel in a large window. For the URL, you might try math.hws.edu/eck/index.html; not all URLs will work, but many will. Consider copy-and-pasting a URL from the location box in a Web browser.
Your job is to improve the program by making it "crawl" the web. When it finds a link that leads to an image, it should still download the image and add it to the collage. But now when it finds a link that leads to another web page, it should download that web page, find any links on that page, and put them into a queue of URLs for later processing. In this way, the crawler could in theory eventually visit all the web pages that are linked, directly or indirectly, to the start page. (Of course, it would have to run for a long time and have a lot of memory!)
To perform well, the program will use several threads that will work simultaneously to download things from the web. This means that to start crawling the web, the program will create and start several download threads. Each thread will run in an infinite loop. In the loop, the thread repeatedly takes a URL from the URL queue and processes that URL. The method processURL() in WebCollage.java, already does some of the necessary processing.
For reasons that we will discuss in class, it works better if there is also a queue of downloaded images. The download threads put any images that they find into the image queue. Another thread takes images from the image queue and adds them to the college. (Essentially, the image queue acts as a buffer that keeps a supply of waiting images on hand.) The design of the system looks something like this:
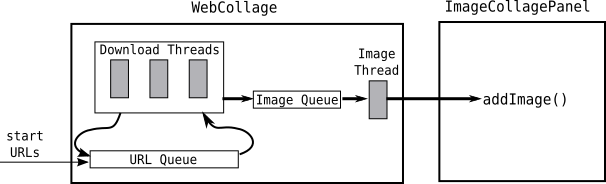
Since the queues that are used in the program are shared by all the threads, they need synchronization. You will use Java's standard queues that already have built-in synchronization, LinkedBlockingQueue and ArrayBlockingQueue. We discussed these these classes in class on Wednesday.
As a final note, you don't want the program to visit the same URL more than once. This means that you must keep track of the URLs that you have already found. If you find the same URL again, it should not be added to the queue the second time. The program will used a HashSet<URL> to keep track of the URLs that have already been found. The set also requires synchronization, but in this case, the synchronization is not built into the class and you will have to implement it by hand.
Writing the Web Crawler
Time to start working on the program. First of all, create the global variables that you need: a HashSet<URL> to hold the visited URLs, a LinkedBlockingQueue<URL> to hold the list of URLs that are waiting to be processed, and an ArrayBlockingQueue<BufferedImage> to hold the list of images that are waiting to be added to the collage. You can experiment with the length of the ArrayBlockinQueue, but 25 is a reasonable value to try.
(Note: We use a LinkedBlockingQueue for the URL queue so that threads will never be blocked from adding URLs to that queue (which could brign the whole process to a halt). We use an ArrayBlockingQueue for the image queue since it doesn't make sense to allow the list of waiting images to grow arbitrarily big. The fact that threads can be blocked from adding things to the image queue will act as a "throttle" on the whole process and will help to stop the program from download unnecessarily huge amounts of data.)
You will need a method to check whether a URL is new or has already been found. The check is done using the hash set and requires synchronization. Assuming that the hash set is named visitedURLs, you can use this method:
private static boolean isNewURL(URL url) {
synchronized(visitedURLs) {
if (visitedURLs.contains(url))
return false;
else {
visitedURLs.add(url);
return true;
}
}
}
You will need a subclass of Thread to define the thread that removes images from the image queue and adds them to the collage panel. The thread should use the take() method of the image queue to remove an item from the queue. Recall that this method will block if the queue is empty. If that happens, the thread will wait for an image to appear in the queue before proceeding. The thread should put a delay between images. This will prevent the whole system from running too fast and sending a lot of web requests too quickly. (Some web sites will get annoyed at that and might even see it as an attack and ban your IP address.) Here is my image adder thread class, which you are welcome to use.
private static class DrawImageThread extends Thread {
public void run() {
while(true) {
try {
BufferedImage img = imageQueue.take();
collagePanel.addImage(img);
System.out.printf(
"ADDED IMAGE. Queue Sizes: links = %d, images = %d\n",
urlQueue.size(), imageQueue.size());
Thread.sleep(500);
}
catch (Exception e) {
}
}
}
}
You will need a similar thread class for the download threads. They should remove URLs from the URL queue and process them. There is the processURL() method for processing URLs. You will have to make some changes to that method; look for the TODO's. For processing HTML web pages, take a look at how LinkParser.grabReferences() is used in the main() routine, and see the comment on that method in LinkParser.java.
Finally, in order to get the whole process going, the startCrawler() method will have to create the threads, start them, and add the original list of URLs to the URL queue. Remember that there will be only one draw image thread, but there will be several download threads. I used 25 download threads, but you can experiment with the number.
Some suggestions for experimentation: You might get more variety in the images if you put a limit on the number of links that you will save from any individual page. You might find that sometimes you won't get any new images for a while. This can happen because you have encountered a lot of pages that don't contain many images. Increasing the size of the image queue and/or the number of download threads might help. You might try using math.hws.edu/eck/cs225/ as your starting URL.
Threads for Your Web Server
This is not a required part of the lab, but you might get extra credit on the previous lab. If you have time, you might want to add threads to the Web server from Lab 11. In class, we talked about making a new thread to handle each connection request. A better idea is to have a "thread pool" (a group of connection-handling threads). All of the threads in the thread pool should be created and started in the main() routine, before the server starts accepting connections. When a connection request is accepted in the main() routine, the server would simply put the socket into an ArrayBlockingQueue<Socket>. Each thread would run in an infinite loop. Inside the loop, it would take a Socket from the ArrayBlockingQueue and call handleConnection(socket).