As we have been discussing in class, the project for this week's and next week's labs is to create a program that will crawl the web looking for images and will create a collage of the images in a window. This is a team project. You will be randomly assigned to a team of two or three students when you arrive at the lab. The project is designed so that you do not need to coordinate closely with your fellow team members -- if you assign tasks to team members during lab today, you should be able to work separately for the rest of the week, if you prefer to do things that way. You also have the option of working together more actively if you want. During next week's lab, you will assemble the completed program, and add a few finishing touches.
The common project that your team is working on will be shared in a CVS repository to which you all have access. I would also like to have access to this repository. You should begin the lab by creating the repository: One team member should create the repository in his or her home directory, and set it up for access by me and by the other team members. The commands for this would be something like:
mkdir cvs-webcollage
fs setacl cvs-webcollage -acl eck all
fs setacl cvs-webcollage -acl yy8888 all
fs setacl cvs-webcollage -acl xx7777 all
cvs -d /home/zz9999/cvs-webcollage init
where zz9999 is the user name of the person who is creating the repository and yy8888 and xx7777 are the IDs of the other team members who will need access to the repository. You can use any name for the directory that you want.
After the CVS repository has been created, one of the team members should create a project in Eclipse named "lab7". You add the webcollage directory from /classes/s10/cs225 to that project. The person who created the project should "Share" it into the CVS repository, and the other team members should "Import" the project from CVS into their Eclipse workspaces. If you need a refresher on how to do this, look back at last week's lab. You should also make sure that you understand "Committing" and "Updating" CVS projects, since that is how team members will share their work.
After you make sure the CVS repository is working, you should decide which part of the project each team member will take responsibility for. You also need to discuss how the connections between the parts of the program will be made once the individual parts are complete.
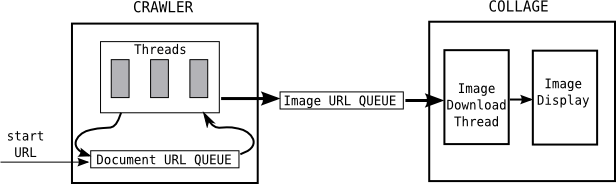
In class, we looked at how the project can be broken into two parts, for a two-person team, or three parts, for a three-person team:

Remember that you will use the ArrayBlockingQueue class to implement the queues. For the three-part project, the image queue will contain BufferedImages. Don't make the queue too long, since BufferedImages can use a lot of memory and you don't want to keep too many of them in memory.
Even if you are working in a group of two, you can choose to implement the three-part version, if you like.
The rest of this web page has some suggestions and hints for each part of the project.
For this part of the program, you will need the class LinkGrabber, which is already in the webcollage package. This class defines a single static method that can get the content of a web page and parse it, looking for URLs. The method places any URLs that it finds into two parameters of type ArrayList<URL>. It also has a parameter of type URL giving the web address that it is to process:
LinkGrabber.parseContent(url, imageURLList, documentURLList);
You have to create the array lists and pass them to the method when you call it. (You want the lists to be empty before you call the method.) The method drops potential image URLs into the imageURLList and potential links to web pages into documentURLList.
You will need to define a Thread class to define threads that will do the downloading and parsing (using LinkGrabber). Create several threads of this type and start them running.
To avoid processing the same URL twice, you can keep a set of URLs that have already been encountered. Use a variable of type HashSet<URL>. HashSet is defined in the package java.util. A HashSet represents a set of objects. It has methods add(object) for adding an item to the set and a method contains(object) for checking whether a given object is already in the set. That's all that you really need to know about it. It's very easy to use.
The simple class TestCrawler, in package webcollage.test will help you to test your crawler before the rest of the program is written. You will have to write a small main program to run the test (possibly adding it to TestCrawler.java).
If you are working on the Image Downloader part of the three-part version of the project or the Collage part of the two-part version, you will need to download images from URLs. Fortunately, this is very easy. The ImageIO class in the package javax.imageio defines a static method that attempts to read a BufferedImage from a URL:
BufferedImage img = ImageIO.read(url);
This method might throw an exception of type IOExcption if an error occurs. It might return null if it does not find an image at the given url. An it will take some indeterminate amount of time to execute (which is why it's a good idea to do the download in a thread).
(There is one potential problem here. The Web contains some very large images, many megabytes in size. You might want to avoid downloading images over some set size limit. We can talk about how to do that if you want.)
If you are writing the Collage part of the project, either for the two-part or three-part version of the project, you will need to create a thread that will retrieve items from an ArrayBlockingQueue and process them. For the three-part version, you get an already-downloaded BufferedImage. For the two-part version, you get a URL, and you have to download the image yourself. In any case, you end up up with a BufferedImage.
You should add a delay to the thread between images, to avoid flooding them at full speed onto the screen. A 1/2 or 1/3 second delay should work. You can add a delay like this:
try {
Thread.sleep(N); // Sleep for N milliseconds.
}
catch (InterruptedException e) {
}
Your goal is to write a GUI program that displays a "collage" of images. That is, it should draw the stream of images, one at a time, to an off-screen canvas and call the repaint() method after each image, to show the change on the screen. The image should be placed in a random location. I suggest that you pick a random point for the center of the image, to get them spread out evenly. I also suggest that if the image is too big, say more than 1/3 the size of the panel, then you should scale it down when you draw it. The technique for doing that was covered in class.
One of the simple classes TestImageConsumer or TestImageURLConsumer, in package webcollage.test will help you to test your collage before the rest of the program is written. The first class generates a stream of BufferedImages in an ArrayBlockingQueue; the second generates a stream of potential image URLs.
If you are writing the Image Downloader part of the three-part version of the project, you will need to take image URLs from an ArrayBlockingQueue that connects your part of the project to the first part. And you will have to put BufferedImages that you download into an ArrayBlockingQueue of images that connects your part to the third part of the project.
You will need to write a thread class that downloads images, taking image URLs from one queue and dropping downloaded images into the other queue. You should create several such threads and start them all running.
The simple class TestImageURLConsumer, in package webcollage.test will help you to test your crawler before the rest of the program is written. It generates a stream of image URLs into an ArrayBlockingQueue.